


Introduction: This article is shared by Sun Xiaoguang, the person in charge of Zhihu technology platform, and mainly introduces the construction practice of Zhihu Flink data integration platform. The content is as follows: 1. Business scenario; 2. Historical design; 3. Design after full shift to Flink; 4. Planning of future Flink application scenarios.
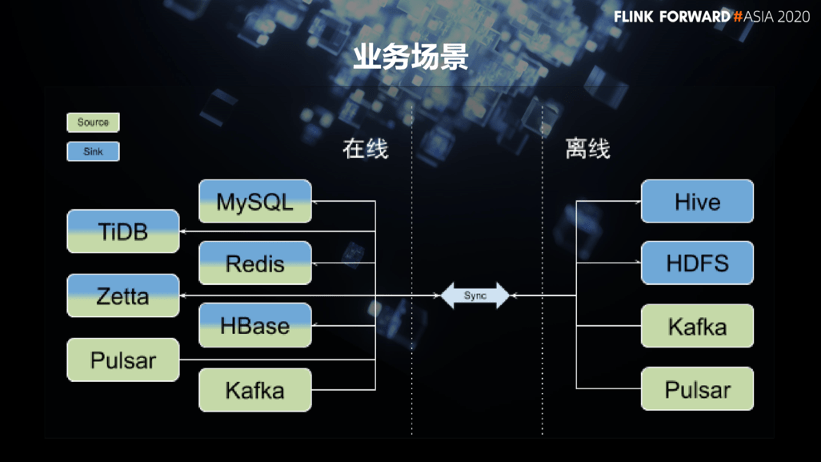
This article is shared by Sun Xiaoguang, the person in charge of Zhihu technology platform, and mainly introduces the construction practice of Zhihu Flink data integration platform. The content is as follows: 1. Business scenario I am very happy to share with you some of the gains in the process of refactoring the previous generation data integration platform based on Flink. As a link to connect various heterogeneous data, the data integration platform needs to connect to a variety of storage systems. Different technology stacks and different business scenarios will put forward different design requirements for the data integration system. Let’s first look at the business scenario of internal data integration in Zhihu. Similar to many Internet companies, Zhihu’s online storage systems were mainly MySQL and Redis in the past, and HBase was also used for some businesses with relatively large data levels. With the evolution of technology in recent years, we have started the migration from MySQL to TiDB. Similarly, we have also begun to evolve HBase to Zetta based on the TiKV technology stack. In terms of offline storage, most scenarios are supported by Hive tables. From online storage to offline storage, there are very strong data synchronization requirements during this period. In addition, there is also a large amount of streaming data, such as the data in the messaging system, and we also hope that it can be connected with various online or offline storage systems. In the past, Zhihu mainly used Kafka to support streaming data. Recently, Pulsar has also been introduced. There is a strong demand for data exchange between these two sets of message systems and storage systems.

- First of all, from a technical point of view, the diversification of data sources will put forward higher requirements for the connection expansion capabilities of the data integration system. Moreover, the next-generation storage system not only brings stronger capabilities to the business, but also releases the pressure of the business, which in turn promotes the accelerated expansion of data. The rapid growth of data level puts forward higher requirements on the throughput and real-time performance of the data integration platform. Of course, as a basic data-related system, data accuracy is the most basic requirement, and we must also do it well.
- In addition, from the perspective of process management, we need to understand and integrate the data scattered across different business teams, manage well and ensure the security of data access, so the entire data integration process is relatively complicated. Although platformization can automate complex processes, the inherent high cost of data integration cannot be completely eliminated in a platform-based manner. Therefore, improving the reusability and manageability of the process as much as possible is also a challenge that the data integration system needs to continue to deal with.


- From a technical perspective, we need to support a variety of storage systems that Zhihu has been put into use and will be promoted in the future, and have the ability to integrate the diverse data in these systems. In addition, we also need to ensure the reliability and accuracy of data integration under the premise of meeting high throughput and low scheduling delay.
- From the perspective of the process, the ability of the existing system infrastructure can be reused by integrating the metadata of various internal storage systems and the scheduling system to achieve the purpose of simplifying the data access process and reducing user access costs. We also hope that we can provide users with a means to meet their data needs in a platform-based manner, thereby improving the overall efficiency of data integration.
- From the perspective of improving task manageability, we also need to maintain the blood relationship of the data. Let the business better measure the relationship between data output, more effectively evaluate the business value of data output, and avoid low-quality and repetitive data integration work. Finally, we need to provide systematic monitoring and alarm capabilities for all tasks to ensure the stability of data output.

2. Historical design
Before Zhihu’s first-generation data integration platform took shape, a large number of tasks were scattered in crontab maintained by various business parties or various scheduling systems built by themselves. In such an unmanaged state, it is difficult to effectively guarantee the reliability and data quality of various integration tasks. Therefore, at this stage, what we have to solve most urgently is the management problem, so that the data integration process can be managed and monitored.
Therefore, we have integrated the metadata system of various storage systems so that everyone can see all the company’s data assets in a unified place. Then, the synchronization tasks of these data are managed uniformly in the dispatch center, and the dispatch center is responsible for the dependency management of the tasks. At the same time, the dispatch center monitors the key indicators of the task and provides abnormal warning capabilities. At this stage, we used Sqoop, which was widely used in the past, to synchronize data between MySQL and Hive. And in the later stage of platform construction, with the emergence of streaming data synchronization requirements, we introduced Flink to synchronize Kafka data to HDFS.
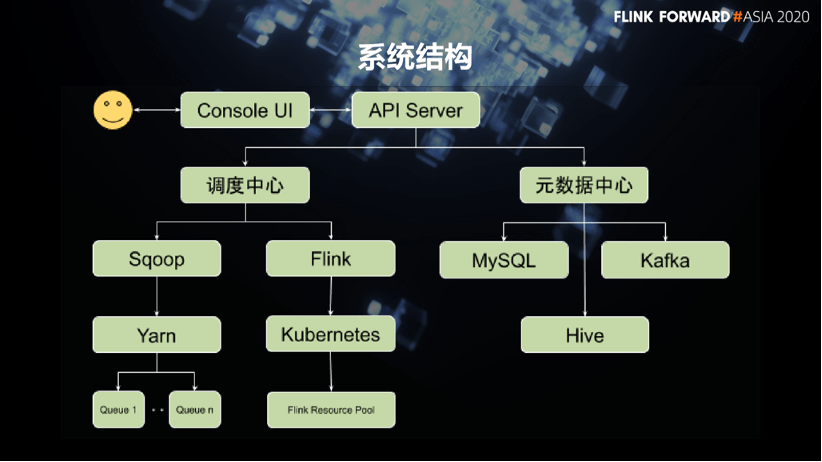
When building the first-generation integration platform, we made a choice of technology selection, whether to continue to use the widely verified Sqoop or to migrate to other optional technical solutions. Compared with Sqoop, Alibaba’s open source DataX is a very competitive opponent in this field. If you compare these two products horizontally, you can find that they have advantages over each other in different aspects.
- For example, Sqoop has MapReduce-level scalability and native Hive support on the system scale. But Sqoop also has the disadvantage of not having abundant data source support and lack of some important features.
- And DataX provides a very rich data source support, built-in the very important speed limit ability of the data integration system, and its easy customization and expansion capabilities brought by its good design. But it also has the shortcomings of no cluster resource management support and lack of native Hive Catalog support.
In the state of the day, none of these two products had an absolute advantage compared to each other. So we chose to continue to use Sqoop, and maintaining the use of Sqoop also saved us a lot of investment in the verification process. Therefore, the first-generation data integration platform completed the development and verification and went online in a very short time.

With the launch and maturity of the first-generation data integration platform, it has well supported the company’s data integration business needs and achieved significant benefits. So far, there are about 4000 tasks on the platform, running more than 6000 task instances every day, and synchronizing about 8.2 billion pieces of data with a total of 124TB.
With the help of the platform, the data access process has been greatly simplified, providing users with the ability to self-solve data integration needs. In addition, the platform can be supplemented with necessary regulatory constraints and security reviews on key process nodes. While improving the management level, the overall security and data quality have also been significantly improved.
With the flexibility of Yarn and K8s, the scalability of integration tasks has also been greatly improved. Of course, as the first-generation system to solve the problem from 0 to 1, it will inevitably be accompanied by a series of problems. such as:
- The inherent high scheduling delay problem of Sqoop’s MapReduce mode
- Data skew caused by uneven distribution of business data
- The inactive community has caused some issues to be unsolved for a long time
- Sqoop code design is not ideal, resulting in weak scalability and manageability problems.

Third, turn to Flink
In contrast to Sqoop, Flink is used to support the integration of Kafka messages to HDFS data. It has gained more trust with its excellent reliability and flexible customization. Based on the confidence established for Flink by the task of streaming data integration, we began to try to fully turn to Flink to build the next-generation data integration platform.
Although Flink is the best candidate in the evolution of this platform, we have re-investigated the available technical solutions on the market based on the situation at that time. This time we compared the Apache NIFI project and Flink in many aspects, from a functional point of view:
- Apache NIFI is very powerful and completely covers our current data integration needs. But precisely because it is too powerful and self-contained, it also brings a high integration threshold. Moreover, the inability to use the existing Yarn and K8s resource pools will also bring additional resource pool construction and maintenance costs.
- In contrast, Flink has a very active and open community. It already has a very rich data source support at the time of project approval. It can be expected that its data source coverage will be more comprehensive in the future. Moreover, as a general computing engine, Flink has a powerful and easy-to-use API design. It is very easy to perform secondary development on this basis, so its advantages in scalability are also very prominent.
Finally, based on our recognition of the goal of batch flow integration, the unification of the big data computing engine technology stack at Zhihu in the future is also an extremely attractive goal.

Based on these considerations, in this round of iteration, we have chosen to use Flink instead of Sqoop. Based on Flink, we have fully implemented the functions of the previous Sqoop and rebuilt a new integration platform.
As shown in the figure below, the orange part is the part that has changed in this iteration. In addition to Flink, which appears as the protagonist, we have also developed data integration functions for three storage systems: TiDB, Redis, and Zetta during this round of iteration. On the messaging system side, Pulsar’s support was obtained directly from the community. When we started the development work, Flink has evolved to a relatively mature stage, with native support for Hive built in. The entire migration process did not encounter too many technical difficulties and was very smooth.
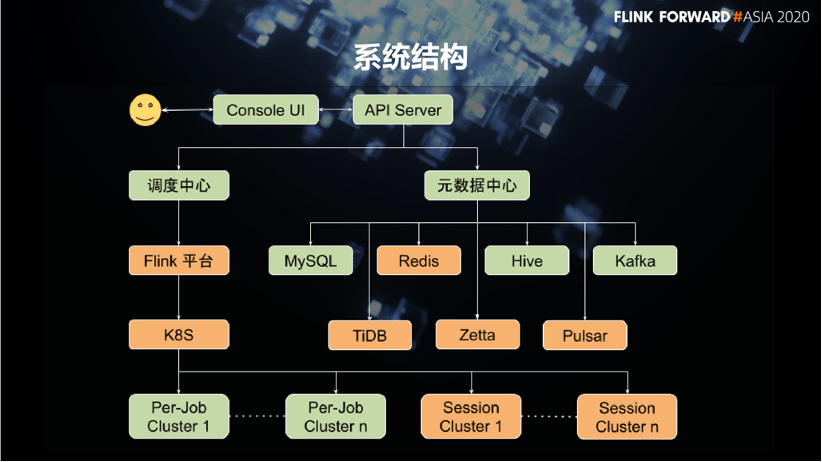
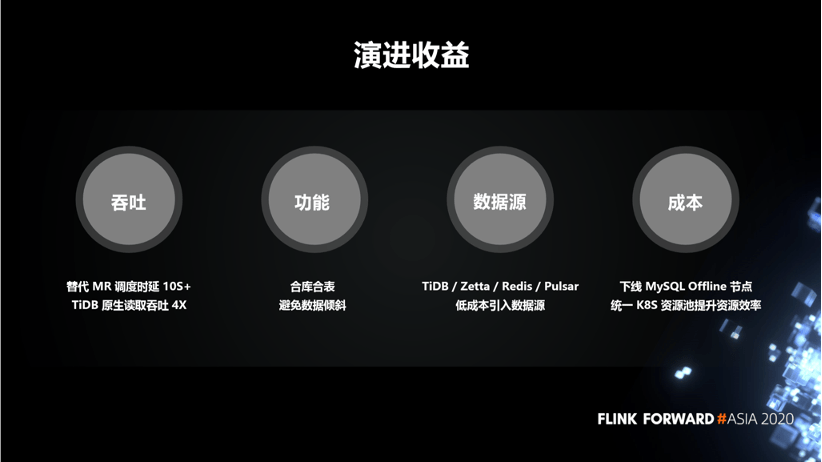
The migration of Flink has brought us many benefits.
- First of all, from the perspective of maintainability, compared to Sqoop, it has a very significant improvement. As shown in the figure below, the left side is the task definition when using Sqoop in the past. Here is a lot of unstructured and error-prone original commands. However, Flink only needs to use SQL to define a source table and a target table and then cooperate with the write command to define the task. The comprehensibility and debuggability of tasks are much better than before, and it has become a mode that end users can understand. Many problems no longer require the cooperation of platform developers to investigate, and users can solve many common task exceptions by themselves.

-
In terms of performance, we have also made many targeted optimizations.
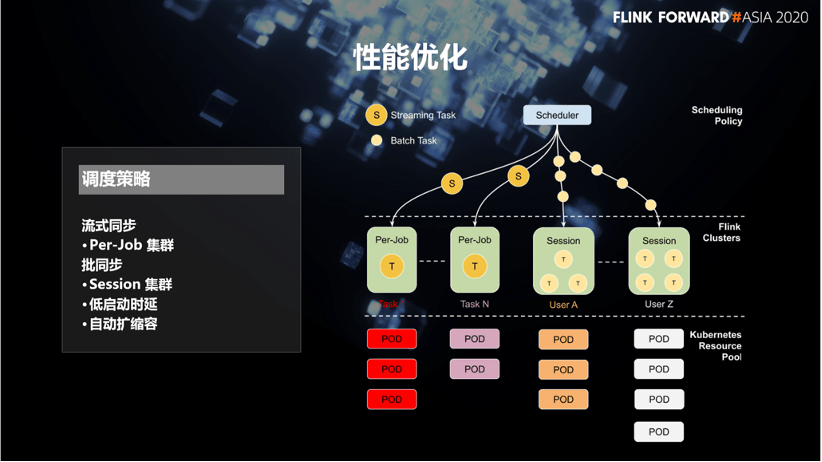
2.1 Scheduling strategy
The first is the optimization of scheduling strategy. In the first-generation integrated platform, we only use Flink to synchronize streaming data, so task scheduling completely uses Per Job. Now the platform supports both Session and Per Job hybrid scheduling modes. Therefore, the Per-Job mode will continue to be used for streaming tasks that access data from the message system, while batch synchronization tasks use Session mode to reuse clusters to avoid Time-consuming cluster startup improves synchronization efficiency.
Of course, there are also a series of challenges in using Session clusters in such scenarios, such as changes in resource requirements caused by continuous changes in workload as tasks are submitted. Therefore, we have built an automatic expansion and contraction mechanism to help the Session cluster cope with the changing load. In addition, in order to simplify the billing mechanism and isolate risks, we have also created private Session clusters for different business lines to serve the data integration tasks of the corresponding business lines.
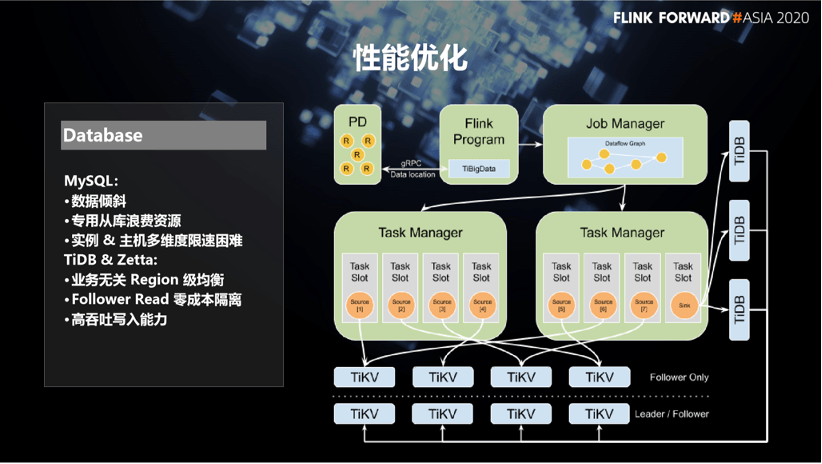
2.2 Database
In terms of relational databases, we have adopted the common JDBC method to synchronize data with MySQL, but this method also has some inherently difficult problems to solve.
- For example, the data skew problem caused by the uneven spatial distribution of business data in the primary key dimension.
- Another example is the waste of resources and management costs caused by a dedicated synchronization slave library built to isolate online and offline workloads.
- And because of the many different specifications of MySQL instances, it is very difficult to reasonably coordinate the instances of multiple concurrent tasks and the host where the instances are located. It is also very difficult to carry out reasonable speed control.
In contrast, considering the trend of fully migrating data from MySQL to TiDB. We developed the native TiDB Flink connector to take full advantage of the TiDB architecture.
- First of all, the region-level load balancing strategy can ensure that for any table structure and any data distribution, synchronization tasks can be split with region as the granularity to avoid data skew problems.
- Secondly, by setting a copy placement strategy, a follower copy can be uniformly placed on the data in the offline data center. Furthermore, while keeping the number of original target copies unchanged and without additional resource costs, the ability of follower read is used to isolate the load of online transactions and data extraction.
- Finally, we also introduced a distributed data submission method to improve the throughput of data writing.
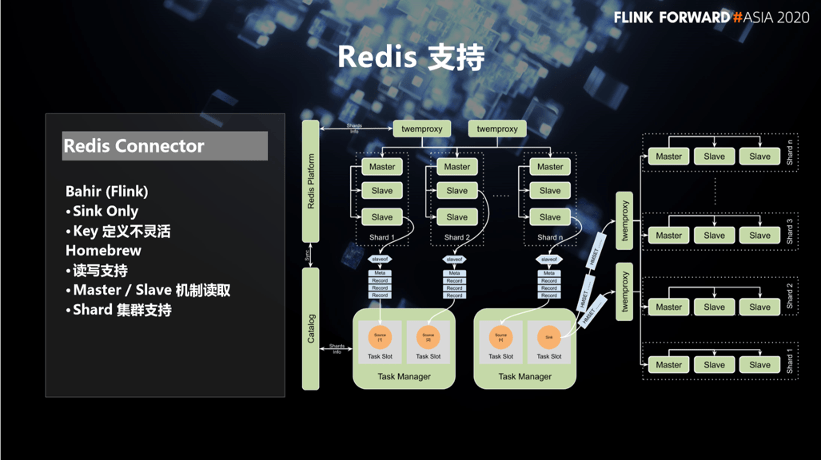
- Finally, it provides data integration capabilities for Redis, which is widely used internally. The Flink community already has a Redis connector, but it currently only has write capabilities and it is difficult to flexibly customize the key used for writing. So we re-developed a Redis connector based on our own needs, and also supports Redis as Source and Sink.
Also in order to avoid the data extraction process from affecting online transactions, we used Redis’s native master/slave mechanism to obtain and parse RDB file extraction data on the data reading path, and obtained a data extraction throughput of about 150MB per second for a single instance. And thanks to the metadata of the internal storage system, we can not only support the data extraction of the sharded Redis cluster, but also select only the slave node of each shard as the data extraction source to avoid the pressure on the master node due to extraction.
This time, it turned to the evolution of Flink, which solved many problems of the previous generation data integration platform, and obtained very significant benefits.
Fourth, Flink is the future
Looking back, the input-output ratio of this full-scale Flink evolution is very high, which further strengthens our confidence in “Flink is the future”. At present, in addition to data integration scenarios in Zhihu, Flink is also used in timeliness analysis of search queries, data processing of commercial advertisement clicks, and real-time data warehouses of key business indicators.
In the future, we hope to further expand the use scenarios of Flink in Zhihu and build a more comprehensive real-time data warehouse and systematic online machine learning platform. We also hope that batch and flow will be integrated, so that large-scale batch tasks such as report and ETL can also be implemented on the Flink platform.
Based on the construction model of Zhihu’s big data system and the overall resource input, it is a very suitable choice for Zhihu to close the technology stack to Flink in the future. As users, we very much look forward to witnessing the achievement of Flink’s goal of batching and streaming in the future. At the same time, as a member of the community, we also hope to contribute to the achievement of this goal in our own way.

This article is the original content of Alibaba Cloud and may not be reproduced without permission.



You must log in to post a comment.