























































Source丨Qubit (ID: QbitAI)
Author丨Fengse Fish and Sheep
Collected all the new crown machine learning “watch movies” papers, Nothing works for one article ? !
Just as the news that “two medical staff in Guangzhou tested positive for nucleic acid” once again affected the nerves of the big guys, a new study from the University of Cambridge also ignited a barrel of explosives on the Internet.
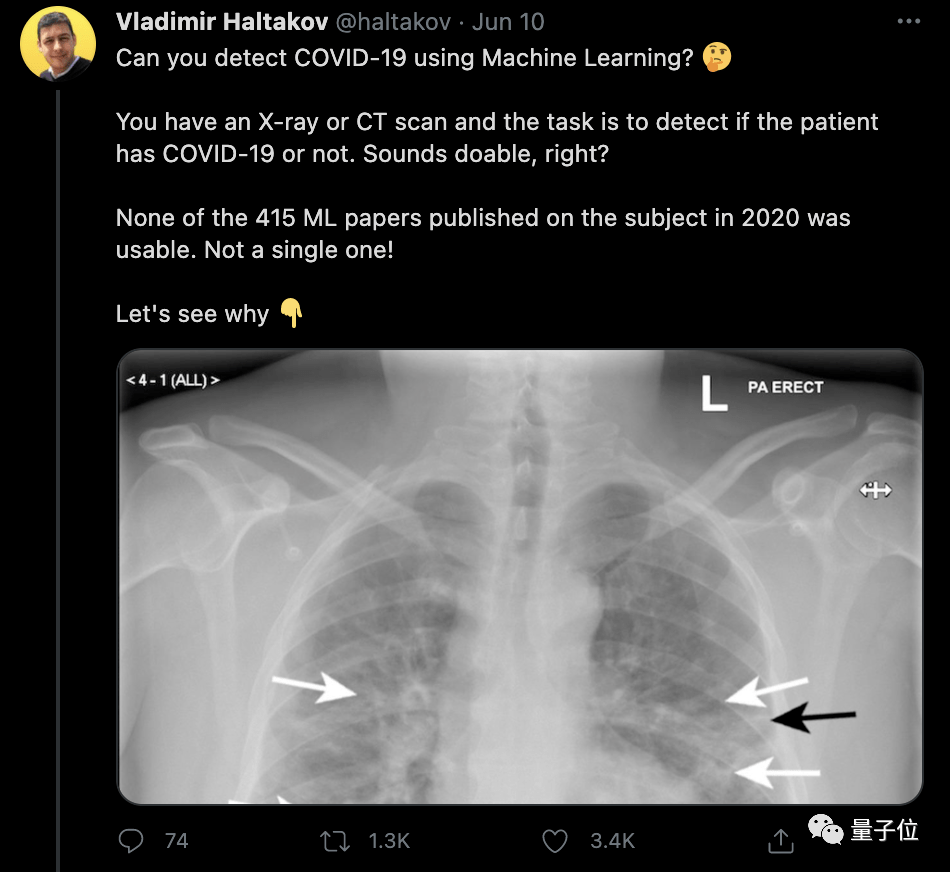
Since the beginning of the epidemic, many researchers in the field of machine learning hope to use the power of AI to help medical staff better protect themselves:
From January to October last year, more than 2,000 related papers were published.However, just when AI is more mature Watch a movie Field, Cambridge University’s conclusions are surprising:
The collected papers on the use of AI for medical image detection and diagnosis of the new coronavirus have major flaws and deviations, and there is no possibility of clinical use. The collected papers on the use of AI for medical image detection and diagnosis of the new coronavirus have major flaws and deviations, and there is no possibility of clinical use. The paper has been published on Nature Machine Intelligence.  And such “cruel” results can be said to have stirred up waves with one stone. Experts and scholars have reposted the discussion, and it has also triggered heated discussions among netizens on social media.
And such “cruel” results can be said to have stirred up waves with one stone. Experts and scholars have reposted the discussion, and it has also triggered heated discussions among netizens on social media.  Many relevant practitioners said: “This has taught us an important lesson.”
Many relevant practitioners said: “This has taught us an important lesson.”  What is going on? Why can’t it be used? Specifically, the researchers at the University of Cambridge initially used the “machine learning model” and “CXR models” in the preprinted paper platforms such as bioRxiv, medRxiv, and arXiv, as well as the EMBASE and MEDLINE databases.(Chest X-ray photo)/CT image diagnosis, prediction” such keywords, collected 2212 Related studies.
What is going on? Why can’t it be used? Specifically, the researchers at the University of Cambridge initially used the “machine learning model” and “CXR models” in the preprinted paper platforms such as bioRxiv, medRxiv, and arXiv, as well as the EMBASE and MEDLINE databases.(Chest X-ray photo)/CT image diagnosis, prediction” such keywords, collected 2212 Related studies. 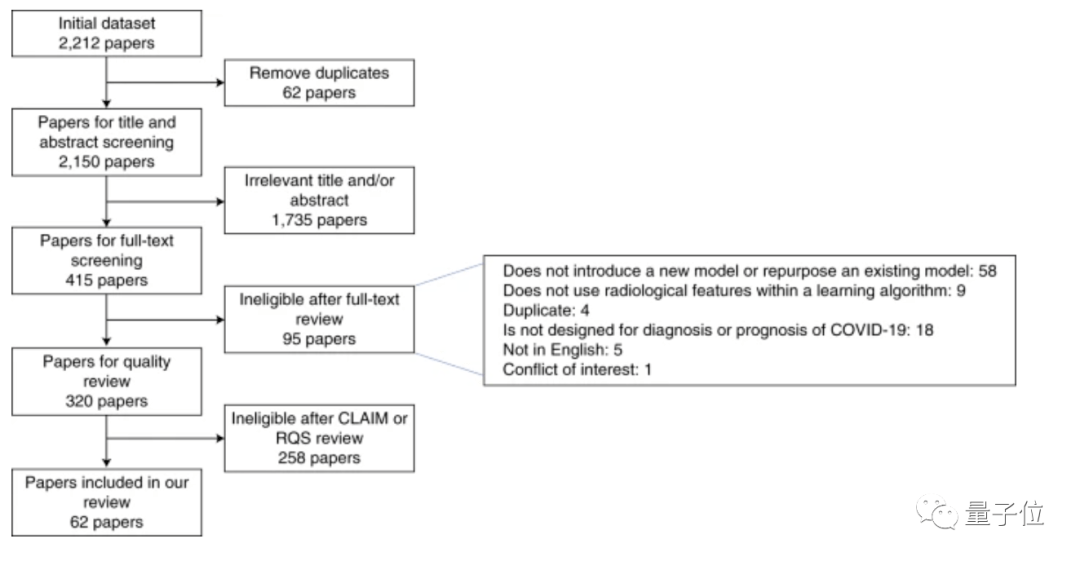 After excluding papers that lack external verification, ignoring data sources, or incomplete model training information, the papers that passed the preliminary screening were: 415 articles . And to further improve the requirements for papers, such as excluding RQS(Radioactive quality score)<6, failed to pass CLAIM(Medical imaging artificial intelligence checklist)After the model, the papers selected for the final review stage are 62 Stories . And these 62 articles, Have no potential clinical application value . In response, one of the authors of the paper, Dr. James Rude from the University of Cambridge School of Medicine, said: The international machine learning community has made tremendous efforts to help respond to the Covid-19 epidemic. These early studies gave us some hope, but their method and reporting deficiencies are very common. None of the papers we reviewed achieved the robustness and repeatability necessary to support clinical applications. The international machine learning community has made tremendous efforts to help respond to the Covid-19 epidemic. These early studies gave us some hope, but their method and reporting deficiencies are very common. None of the papers we reviewed achieved the robustness and repeatability necessary to support clinical applications. Of the 62 papers, 55 were found to be at high risk of bias due to various problems, including relying on public data sets, many of which were suspected of being positive for Covid-19 and were not detected in CT images.
After excluding papers that lack external verification, ignoring data sources, or incomplete model training information, the papers that passed the preliminary screening were: 415 articles . And to further improve the requirements for papers, such as excluding RQS(Radioactive quality score)<6, failed to pass CLAIM(Medical imaging artificial intelligence checklist)After the model, the papers selected for the final review stage are 62 Stories . And these 62 articles, Have no potential clinical application value . In response, one of the authors of the paper, Dr. James Rude from the University of Cambridge School of Medicine, said: The international machine learning community has made tremendous efforts to help respond to the Covid-19 epidemic. These early studies gave us some hope, but their method and reporting deficiencies are very common. None of the papers we reviewed achieved the robustness and repeatability necessary to support clinical applications. The international machine learning community has made tremendous efforts to help respond to the Covid-19 epidemic. These early studies gave us some hope, but their method and reporting deficiencies are very common. None of the papers we reviewed achieved the robustness and repeatability necessary to support clinical applications. Of the 62 papers, 55 were found to be at high risk of bias due to various problems, including relying on public data sets, many of which were suspected of being positive for Covid-19 and were not detected in CT images. 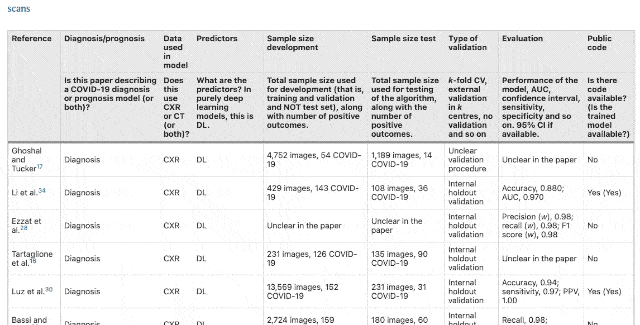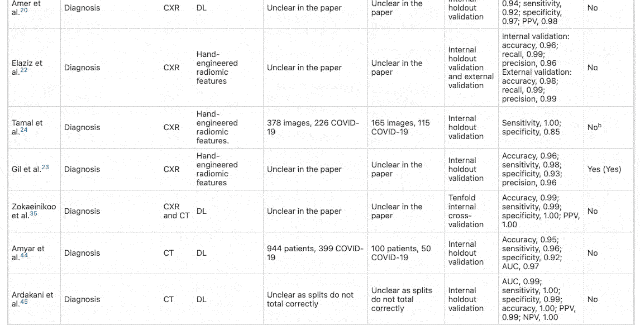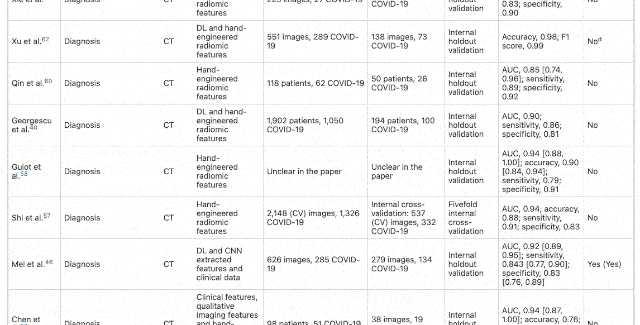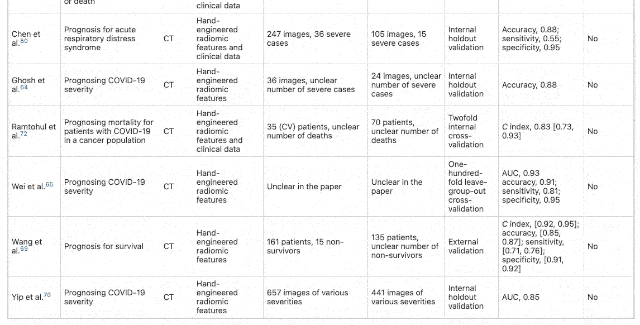 △ Data indicators for each paper All of these models appear to be highly accurate in the study, and they are fully revealed as soon as they arrive in the clinic (for example, different types of patients or imaging scans obtained with different equipment). Behind this “annihilation” is mainly the problem of data sets. Many of these models are trained with very small sample data sets, and some data only come from one hospital. If you change a city to a hospital, this model will not work at all. There are also models that are trained based on the publicly available “Frankenstei Data Set”. The problem with such a large data set is that as time goes by, the data set continues to develop and incorporate new data. These changes are likely to make the original results impossible to reproduce. What’s more, the same data set is used for training and testing.
△ Data indicators for each paper All of these models appear to be highly accurate in the study, and they are fully revealed as soon as they arrive in the clinic (for example, different types of patients or imaging scans obtained with different equipment). Behind this “annihilation” is mainly the problem of data sets. Many of these models are trained with very small sample data sets, and some data only come from one hospital. If you change a city to a hospital, this model will not work at all. There are also models that are trained based on the publicly available “Frankenstei Data Set”. The problem with such a large data set is that as time goes by, the data set continues to develop and incorporate new data. These changes are likely to make the original results impossible to reproduce. What’s more, the same data set is used for training and testing.  Of course, this may not be deliberately done by researchers. For legal and commercial reasons, many medical data sets have to be Keep secret , There are really few large and diverse data for researchers to train and verify. This also makes the machine learning research produced in the health care field particularly difficult to replicate. MIT has done a study: The recurrence rate of medical AI papers is only 23%, compared with 58% in the field of natural language processing and 80% in the field of computer vision. But the data set is only one aspect. There are also problems with improper method design and lack of participation of radiologists and clinicians. For example, a training set with a model uses CT images of children as “non-Covid-19” data, and adults as “Covid-19” data. But in fact, children treated in pediatrics are very different from adults in terms of human anatomy. Such data settings are unreasonable, and the trained model will have large deviations. “Whether you are using machine learning to predict the weather or detect diseases, it is important to ensure that different experts work together and speak the same language so that you can focus on the right issues.” Unfortunately, many models do not allow radiology departments. Doctors and clinicians get involved. In addition, time limit It can also be interpreted as an “excus” for this series of questions. “These obstacles must be overcome, Otherwise, we will face a crisis of trust” Of course, behind the fact that a large number of such papers are published but all cannot be applied, it shows that the paper a There are also problems, such as the lack of in-depth understanding of machine learning by the reviewers, or blind trust in well-known institutions or companies, etc., which led to these papers being passed hastily. But the most important thing is the lack of review institutions Consistent standards To evaluate machine learning research in the medical field. Researchers at the University of Cambridge believe that a common set of standards must be established between authors and reviewers to ensure that the research really solves practical problems.
Of course, this may not be deliberately done by researchers. For legal and commercial reasons, many medical data sets have to be Keep secret , There are really few large and diverse data for researchers to train and verify. This also makes the machine learning research produced in the health care field particularly difficult to replicate. MIT has done a study: The recurrence rate of medical AI papers is only 23%, compared with 58% in the field of natural language processing and 80% in the field of computer vision. But the data set is only one aspect. There are also problems with improper method design and lack of participation of radiologists and clinicians. For example, a training set with a model uses CT images of children as “non-Covid-19” data, and adults as “Covid-19” data. But in fact, children treated in pediatrics are very different from adults in terms of human anatomy. Such data settings are unreasonable, and the trained model will have large deviations. “Whether you are using machine learning to predict the weather or detect diseases, it is important to ensure that different experts work together and speak the same language so that you can focus on the right issues.” Unfortunately, many models do not allow radiology departments. Doctors and clinicians get involved. In addition, time limit It can also be interpreted as an “excus” for this series of questions. “These obstacles must be overcome, Otherwise, we will face a crisis of trust” Of course, behind the fact that a large number of such papers are published but all cannot be applied, it shows that the paper a There are also problems, such as the lack of in-depth understanding of machine learning by the reviewers, or blind trust in well-known institutions or companies, etc., which led to these papers being passed hastily. But the most important thing is the lack of review institutions Consistent standards To evaluate machine learning research in the medical field. Researchers at the University of Cambridge believe that a common set of standards must be established between authors and reviewers to ensure that the research really solves practical problems.  Finally, although a large number of Covid-19 models have been found to be unable to be reproduced for clinical use, researchers at the University of Cambridge said that after some key modifications, these machine learning models can still become powerful tools in the fight against the new crown. They gave some conclusions and suggestions:
Finally, although a large number of Covid-19 models have been found to be unable to be reproduced for clinical use, researchers at the University of Cambridge said that after some key modifications, these machine learning models can still become powerful tools in the fight against the new crown. They gave some conclusions and suggestions:
- Public data set May cause serious risk of deviation, use with caution;
- In order to make the model applicable to different groups and independent external data sets, the training data should be kept Variety and appropriate size ;
- In addition to higher-quality data sets, you also need Reproducible and externally verified In this way, the possibility of the model being promoted and integrated into future clinical trials can be increased.
Public data set May cause serious risk of deviation, use with caution; In order to make the model applicable to different groups and independent external data sets, the training data should be kept Variety and appropriate size ; In addition to higher-quality data sets, you also need Reproducible and externally verified In this way, the possibility of the model being promoted and integrated into future clinical trials can be increased. And said that these obstacles must be overcome, otherwise, where will people’s trust in artificial intelligence start?In addition, due to privacy restrictions, it is difficult to obtain medical data. In addition to federal learning, you can also refer to the latest published on the cover of Nature. Joint learning (Swarm Learning), A medical data sharing technology superior to federal learning.  Is it okay for AI to watch movies? Facing the conclusion of the University of Cambridge, some netizens are worried: Today, the value and credibility of AI/ML are being diluted. When I hear words like “AI solution” and “AI driven”, I even feel nervous. Today, the value and credibility of AI/ML are being diluted. When I hear words like “AI solution” and “AI driven”, I even feel nervous.
Is it okay for AI to watch movies? Facing the conclusion of the University of Cambridge, some netizens are worried: Today, the value and credibility of AI/ML are being diluted. When I hear words like “AI solution” and “AI driven”, I even feel nervous. Today, the value and credibility of AI/ML are being diluted. When I hear words like “AI solution” and “AI driven”, I even feel nervous.  Some netizens believe that this is not unrelated to the current trend of “watering” papers in the field of machine learning.
Some netizens believe that this is not unrelated to the current trend of “watering” papers in the field of machine learning.  However, some netizens objectively analyzed that AI has indeed played a role in medical imaging, but they can’t replace doctors, they are more acting as doctors. assistant And at present, AI has no way to deal with some really difficult situations.
However, some netizens objectively analyzed that AI has indeed played a role in medical imaging, but they can’t replace doctors, they are more acting as doctors. assistant And at present, AI has no way to deal with some really difficult situations. 
 And for what the article talks about data Many netizens agree with the question: Data is not the only problem, but it seems to be the most direct cause. It’s time to build a database like “Protein Bank” for AI models and data sets. Data is not the only problem, but it seems to be the most direct cause. It’s time to build a database like “Protein Bank” for AI models and data sets. In fact, no matter whether you are skeptical about AI medical care or not, now, at least like AI watching movies Such medical services have truly come to the public. Prior to this, colleagues of qubits had asked AI to take a CT scan at Zhongguancun Hospital. In the communication with first-line doctors, the chief doctor in charge of the physical examination center in the tertiary hospital also revealed to us that single-point applications such as the detection of lung nodules have been able to help doctors reduce the burden. There are even radiologists who said, “I don’t use it now (AI assisted viewing), and I’m not used to it.” Stat News commented on this: Machine learning is booming in the medical field, but it is also facing a credibility crisis.
And for what the article talks about data Many netizens agree with the question: Data is not the only problem, but it seems to be the most direct cause. It’s time to build a database like “Protein Bank” for AI models and data sets. Data is not the only problem, but it seems to be the most direct cause. It’s time to build a database like “Protein Bank” for AI models and data sets. In fact, no matter whether you are skeptical about AI medical care or not, now, at least like AI watching movies Such medical services have truly come to the public. Prior to this, colleagues of qubits had asked AI to take a CT scan at Zhongguancun Hospital. In the communication with first-line doctors, the chief doctor in charge of the physical examination center in the tertiary hospital also revealed to us that single-point applications such as the detection of lung nodules have been able to help doctors reduce the burden. There are even radiologists who said, “I don’t use it now (AI assisted viewing), and I’m not used to it.” Stat News commented on this: Machine learning is booming in the medical field, but it is also facing a credibility crisis.
Machine learning is booming in the medical field, but it is also facing a credibility crisis.
So, do you think AI medical care will work?
— Finish —
This article is the original content of the NetEase News•NetEase Featured Content Incentive Program signed account[qubit]. Unauthorized reprinting of the account is prohibited.
This article is reproduced with permission from Qubit (ID: QbitAI ), please contact the original author if you need to reprint
Welcome to forward to the circle of friends.




You must log in to post a comment.